FAERY: An FPGA-accelerated embedding-based Retrieval System
1. 摘要
基于嵌入的检索(EBR)广泛用于推荐系统,以从包含百万个或者更多项目的大型语料库中检索数千个相关候选项。一个好的EBR系统需要同时实现高通量和低延迟,因为高吞吐量意味着节省成本,而低延迟可以改善用户体验.不幸的是,现有的基于CPU和GPU的的EBR的性能由于其固有的架构限制而远非最佳。在下文中,我将首先介绍一个理想而实用的EBR系统是如何工作的,然后基于ideal状况,人们提出并设计的FPGA加速的EBR-FAERY,它实现了实用的理想EBR系统的最佳性能。FAERY由三个关键组件组成:它使用高带宽HBM进行内存带宽密集型语料库扫描,使用数据并行方法进行相似度计算,以及基于管道的方法进行K选择。为了进一步减小硬件资源,FAERY引入了一个过滤器来提前丢弃非Top-K项目。实验表明,在GPU相同显存带宽的情况下,降级后在目标为10ms的延迟目标下,与基于GPU的EBR相比,FAERY仍能达到1.21~12倍延迟低于其以及4.29倍吞吐率高于其的目标。
2. 介绍
2.1 检索与排序
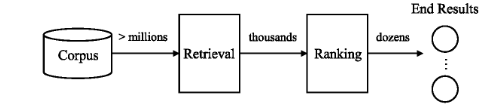
推荐系统已经在许多在线服务中得到广泛采用。为了从包含数百万候选项目的大型语料库中进行推荐,工业大规模推荐系统通常分为两层,即检索和排序。如图所示
 (图1)
(图1)
检索通过简单的算法从庞大的语料库中快速选择数千个相关项目,而排序则利用复杂的算法对检索结果进行更精确的排序,然后从排序的项目中选择数十个。
现实世界的检索系统进行多通道检索:他利用不同通道中的不同策略来检索不同的候选者,然后将其合并和过滤以生成最终的检索结果。在多通道检索策略中,基于嵌入的检索(EBR) 越来越受欢迎。
2.2 EBR检索大致流程
 (图2)
(图2)
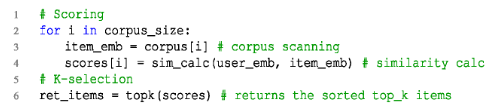
具体来说,如图1所示,EBR算法涉及评分,它扫描语料库以获取所有项目并计算每个项目嵌入和给定查询嵌入之间的相似度分数(例如,通过内积),以及 K-selection ,它根据相似度得分返回Top-K项目。返回的 EBR的Top-K项通常被排序,以简化来自多个通道的合并和过滤检索候选。这种EBR系统的性能很重要。一方面,增加每台EBR服务器的吞吐量会降低整体服务器成本,因为只需要更少的服务器来提供目标每秒查询数(QPS)。另一方面,降低每个EBR服务器的延迟会减少检索时间,这既可以缩短用户的整体等待时间,也可以为排名计算留出更多时间以获得更好的推荐结果[11]。因此,延迟猎杀的吞吐量成为EBR系统的关键指标。
2.3 理想架构
为了实现高延迟限制吞吐量,我们对图1中所示的EBR算法进行了表征,并派生了一个实际理想的EBR硬件架构。具体来说,语料库扫描是一种内存密集型操作,需要大的外部内存容量和高内存带宽。相似度计算和K选择都是计算密集型的。它们应该将内存带宽与跨多个算子实例的数据并行架构相匹配。此外,为了与步骤或操作符之间的计算重叠通信,在K-selection内部和整个EBR数据流中都需要管道并行性。然后,我们通过在批量查询之间共享语料库扫描并提供单独的计算管道来扩展理想架构以支持批量查询.因此,理想的架构实现了最佳的查询延迟,并随着批量大小线性扩展延迟限制的吞吐量
2.4 现状
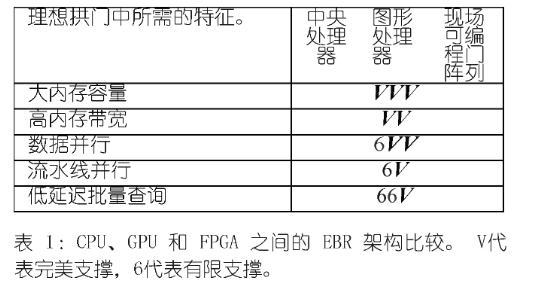
通过将现有的基于CPU和GPU的EBR与理想架构进行比较,我们意识到,不幸的是,由于其固有的架构限制,现有方法都没有实现最佳性能。首先,尽管内存容量很大,但由于内存带宽低,CPU在语料库扫描中表现不佳,并且由于内核数量有限,无法同时很好地支持所需的并行范式。其次,虽然GPU为数据并行提供了更高的内存带宽和海量计算核心,但由于明确的资源边界,GPU并未针对K-selection和整个EBR 数据流所需的管道并行进行优化。
我们观察到FPGA 是一种可编程硬件设备,在一些超大规模云提供商中很容易获得,它具有实际理想EBR架构的所有所需特性。一些现代FPGA配备了大容量高带宽存储器(HBM),非常适合语料库扫描。此外,FPGA 提供足够的片上存储器和完全可编程的计算元件,以便为各种操作员启用适当的并行范式。
2.5 FAERY的优势
FAERY ,这是一种基于FPGA加速嵌入的检索系统,它是理想EBR架构的体现,并实现了高性能。具体来说,FAERY将语料库存储在FPGA的HBM中,为内存带宽密集型的语料库扫描提供了高带宽。FAERY利用语料库管理器在运行时最大化HBM带宽利用率,同时保留内存高效存储并启用在线语料库更新。FAERY遵循理想架构设计数据并行性的相似性计算和管道并行性的K-selection。与理想架构不同的是,FAERY只需要一个K-selection流水线,并根据在K-selection流水线中观察到的独特属性,在其前面添加一个过滤器以显着降低其吞吐量要求。与理想架构相比,过滤器优化通过消除多个K-selection管道降低了FAERY的资源需求。
上述思路使单个基于FPGA的EBR加速器性能良好。为了进一步增强其功能,可以将多个此类加速器卡插入FAERY服务器并协同工作。当一个语料库可以放入单个卡,我们可以通过在多张卡之间复制语料库来扩展聚合查询吞吐量。当语料库太大而无法放入单张卡片时,我们可以将其平均分片到多张卡片中。FAERY支持复制和分片模式,并利用软件前端来调度查询并合并多个加速卡的检索结果。
实验表明,与Nvidia T4 GPU加速的EBR系统相比,在 10毫秒的延迟目标下,具有相同GPL内存带宽的降级FAERY可实现低1.21 x-12.27倍的延迟和高达4.29 倍的吞吐量。
3. 背景与动机
3.1 EBR算法:KNN与ANN
EBR表示带有嵌入的用户查询和候选项目,并将检索问题转换为向量空间中的K-最近邻(KNN)或近似最近邻(ANV)搜索问题。基于KNN的EBR从语料库中搜索准确的k-最近项嵌入,而基于ANN 的EBR通过使用索引等技术牺牲准确性以提高效率来检索近似的最近项嵌入和量化 。
CPU提供有限的内存带宽和计算能力,由于内存访问和计算的巨大成本,CPU在大型语料库上执行KNN搜索具有挑战性。因此,ANN搜索是在业界广泛应用于基于CPU的EBR。相比之下,加速器,例如GPU和FPGA,提供了更高的内存带宽和计算能力,因此这些加速器通常采用KNN搜索来交换内存带宽和计算能力以获得更高的准确性,从而获得更好的推荐质量.
3.2 几乎理想的EBR架构
 (图3)
(图3)
为了最大化延迟限制的吞吐量,理想的架构应该首先实现每个单独查询的最小延迟(相当于批量大小为1的最大吞吐量),然后随着批量大小的增加线性扩展吞吐量,同时保持一致的最小延迟。
在理论上理想的架构中,对于每个查询,我们使用并行的所有项目嵌入进行相似度计算,并在0(1)时间内完成该运算符,然后进行完美的K选择以匹配并行度。这显然是不切实际的,因为它需要并行进行数百万个项目访问和数百万个相似度计算(例如内积)运算符,更不用说K-selection的设计挑战来匹配这种极端并行性。一个实际理想的EBR 应该考虑到现实的硬件限制和我们在下面讨论的EBR特性。
语料库扫描是一个内存密集型操作符。工业语料库的大小高达几GB,扫描如此大的语料库会导致单个查询的数百万次内存访问。因此,语料库存储和扫描需要大的外部内存和高内存带宽。相似度计算是一个计算密集型运算符,它计算用户之间的相似度分数查询和所有项目嵌入。由于不同项目嵌入的计算是独立的,理想的架构应该执行具有数据并行性的相似性计算,以匹配语料库扫描的吞吐量。
K-selection是另一个计算密集型运算符。为了匹配多个相似度计算实例的吞吐量,K-selection还需要多个实例的数据并行性。在单个实例中,K-selection可以通过多种算法实现,其中一种常见的做法是将这个复杂的任务划分为多个步骤,并以流水线方式组织它们。基于这些特性,实现最佳延迟的实际理想EBR架构应该具有用于语料库存储和扫描的大容量和高带宽内存,EBR操作员的适当并行性以使其吞吐量与内存带宽相匹配,以及通信和通信之间的完美重叠。整个管道中的算子计算,以最大限度地减少延迟。
理想的架构可以扩展到支持批量查询,以线性增加延迟限制的吞吐量,如图3所示。关键是在批量中的多个查询之间共享语料库扫描(即,每批次只扫描一次语料库),并以数据并行的方式使用单独的计算管道处理多个查询。通过这种方式,延迟保持不变,如公式1所示,并且延迟限制的吞吐量随批量查询的数量线性增长。实际上,由于资源限制,批量大小不能无限制地增加,因此最大延迟限制吞吐量将受所选平台的可用硬件资源限制。
3.3 FPGA的机会
我们观察到FPGA具有满足理想EBR架构要求的一下特性
- 与GPU类似,高端 FPGA配备了大容量的 HBM(通常为8到32 GB)。典型的HBM是由32个并行DRAM通道组成的堆栈(而CPU中多达8个DDR通道),提供并行内存访问,从而提供高带宽(460 GB/s ) ,从根本上消除了基于CPU的最大内存带宽瓶颈EBR。
- GPU为每个SM提供专有的小型片上存储器不同,FPGA 提供了足够的片上存储器(总共数十MB),所有计算元素都可以访问这些存储器。与仅针对数据并行优化的SIMT内核的GPU不同,FPGA中的海量计算元素和它们之间的互连是完全可编程的,因此它们可以在任何并行策略(数据并行或流水线并行)中进行编排。
 (图4)
(图4)
4. FAERY
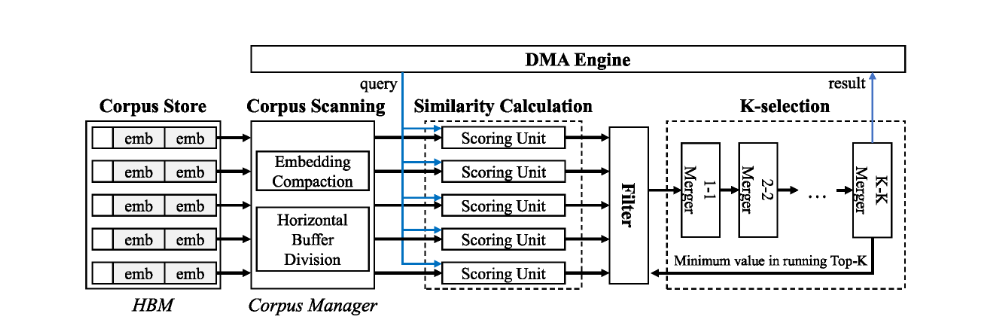 (图5)
(图5)
我们按照理想EBR架构的最理想特性设计FAERY加速器,并进行了一些额外的优化。图5展示了FAERY加速器的架构,包括HBM、语料库管理器、相似度计算、过滤器和K选择等几个主要组件。FAERY将语料库存储在HBM中,并使用语料库管理器进行语料库扫描和更新。FAERY跨多个相似性计算单元应用数据并行性,并在K选择中应用管道并行性 。与理想的EBR架构不同,FAERY不需要多个具有数据并行性的K-selection流水线,这要归功于在K-selection流水线之前插入了一个新的过滤器运算符以降低其吞吐量要求。
4.1 语料库管理器
FAERY将语料库存储在HBM中,并使用语料库管理器进行语料库扫描和更新。语料库管理器旨在满足HBM高带宽利用率的两个目标:最大化单通道性能和最大化多通道并行性。
- 嵌入压缩以最大化单通道性能
- 水平HBM划分以最大化多通道并行性
4.2 相似度计算
相似度计算同时从多个HBM 通道接收多个项目嵌入。为了匹配HBM 的带宽,我们在相似度计算中应用数据并行性,其中多个评分单元(SU)被实例化以并行工作,并且每个评分单元执行相似度计算,例如,在单独的项目嵌入和给定之间的内积查询嵌入。所需的并行SU数量是HBM 通道总数与通道宽度内的最大项目嵌入数的乘积,由于嵌入压缩,可能包含多个项目嵌入。
4.3 K-选择
4.4 筛选
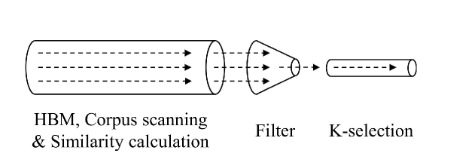 (图6)
(图6)
K-selection管道在运行的Top-K中维护,它不断更新Top-K的所有过去分数,直到当前点。我们观察到,如果K-selection的输入分数不大于运行Top-K 的最小分数,则输入不会改变内部运行的Top-K,因此可以丢弃。基于这一观察,我们设计了一个过滤器来提前丢弃非Top-K分数,这显着减少了发送到K-selection的分数数量。图6显示了FAERY的吞吐量模型,其中语料库扫描和相似度计算设计了数据并行性以匹配 HBM吞吐量,K-selection仅提供单个管道以节省资源,过滤器弥合吞吐量错误-多通道相似度计算与单通道K-选择之间的匹配
4.5 FAERY数据流的完美重叠
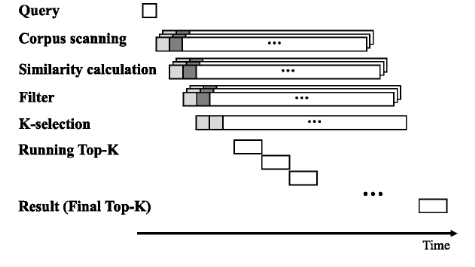 (图7)
(图7)
如上节所述,所有操作员都在一个
流方式,即所有算子在数据开始流入时立即开始处理,运算符与计算完全重叠。因此,该架构中的数据流表现出完美的
重叠,如图7所示。收到查询后,语料库管理器开始语料库扫描,并从32个HBM 通道中获取嵌入的多流,然后在后续循环中进行相似度计算和过滤流。过滤器操作员提前丢弃大部分分数,以便将单个分数流发送到K-selection。随着分数开始
流到K一selection中,运行的Top-K被更新,并在最后一个分数注入K-selection管道后不久作为最终的Top-K结果输出。
FAERY以与理想架构相同的方式支持批处理。多个查询的数据流从同一点开始。因此,延迟保持不变,并且吞吐量与批量大小成线性关系。
5. FAERY server
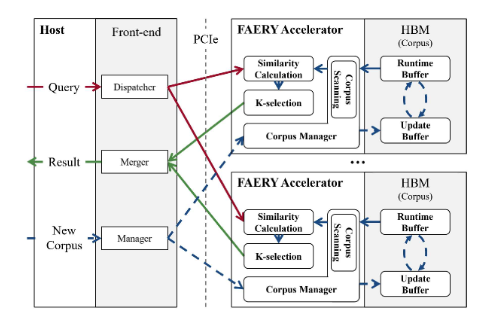
图11展示了FAERY服务器架构,其中包括主机CPU上的软件前端和插入服务器PCie插槽的多个FAERY加速器。
多个FAERY 加速器可以协同工作,以两种模式增强单个加速器的能力:复制和分片。在复制模式下,这些加速器存储同一语料库的不同副本,同时服务不同的查询,以提高查询吞吐量。在分片模式下,多个加速器存储同一个语料的不同分片,同时服务同一个查询,以增加支持的语料大小。运行在主机CPU中的前端负责通过调度器模块进行查询调度和通过合并模块在上述两种模式中合并结果。
当服务器收到新的语料库时,软件前端的管理器模块会处理这个更新请求。它根据上面列出的工作模式确定是否需要进行语料复制或分片,然后将语料副本(或分片)通过PCie发送到相应的加速器。
6. 评估
我们评估FAERY实现的性能,并将其分别与基于CPU和GPU的EBR进行比较。实验表明:
-
FAERY 接近最优查询延迟,并实现
延迟分别比基于CPU和 GPU的EBR低98.09x-118.99x和1.85x-18.81x。与GPU相同显存带宽的降级FAERY仍能达到l。延迟比基于GPU的EBR低2l x -12.27x。 -
在数以十万计的延迟限制(:s lo ms)吞吐量中,FAERY和降级的FAERY比基于GPU的EBR高1倍。分别为33x -6.58x 和0.87 x -4.29x ,而基于CPU的EBR未能满足10 ms延迟目标。
-
FAERY达到 l。与基于GPU的EBR相比,能效提高66 x -8.20 x,成本效率提高1.31 x -6.46x。
-
带有两个加速器的 FAERY服务器在复制模式下提供⒉倍的查询吞吐量,在分片模式下提供2倍的语料库容量,延迟增加不到1.1%。
7. 结论
FAERY是用于基于嵌入的检索(EBR)的领域特定加速器(DSA)。FAERY 的组件:语料库扫描、相似性计算和K选择是使用理想EBR架构所需的适当并行技术安排的。因此,FAERY 没有现有基于CPU和GPU的EBR方法的缺点和性能损失。与基于CPU的EBR 相比,FAERY不仅提供了低延迟和高吞吐量,而且在延迟限制吞吐量方面优于基于GPL的EBR。

1 条评论
表评论2781