我对 Embedding 模型的几个灵魂拷问
最近在学习向量检索,越研究越觉得 Embedding 这个东西"熟悉又陌生"。说熟悉,是因为它无处不在;说陌生,是因为一些看似简单的问题,我其实一直没想清楚。
Q1 维度之谜
为什么 Embedding 的维度总是 768、1536、384?为什么不是 2 的次幂?
这个问题我相信很多人都有过:明明计算机世界里"2 的次幂"无处不在,为什么 Embedding 的维度偏偏是这些"奇怪"的数字?
答案其实藏在 Transformer 的内部结构里。
Transformer 内部的维度公式
Transformer 的注意力机制有一个核心公式:
总维度 (d_model) = 注意力头数 (n_heads) × 每头维度 (d_head)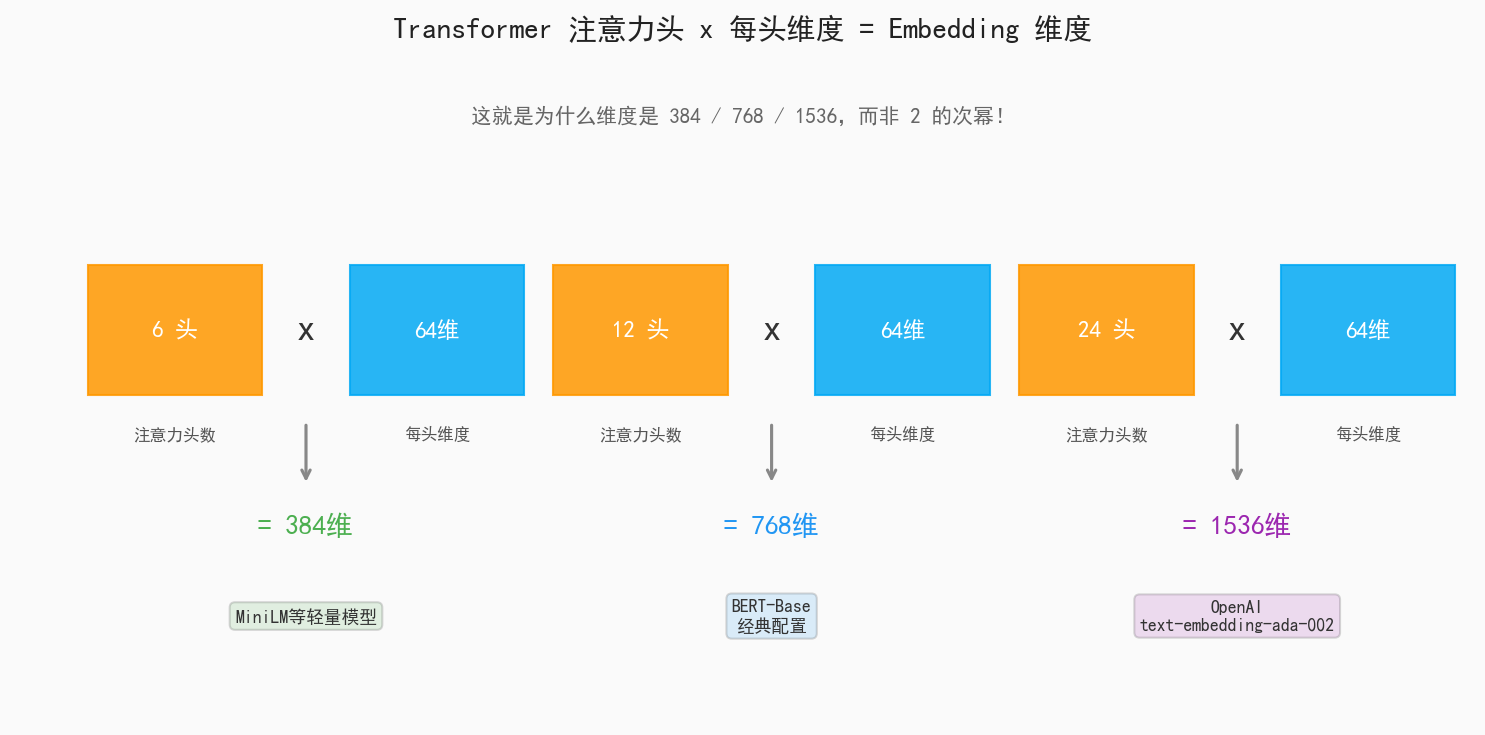
图1:注意力头数 x 每头维度 = Embedding 维度,三种经典配置
你看,1536 不是"随便定"的,而是 24 × 64 = 1536,这是 Transformer 结构推导出来的自然结果。
768 同理:12 × 64 = 768,这是 BERT-Base 的经典配置。384 = 6 × 64,轻量级模型的常见选择。
为什么每头维度偏爱 64?
经验上,d_head = 64 在表达能力、GPU 并行效率和数值稳定性之间取得了很好的平衡——这也是为什么你在大量 Transformer 论文里都能看到这个数字。
GPU 根本不在乎 2 的次幂
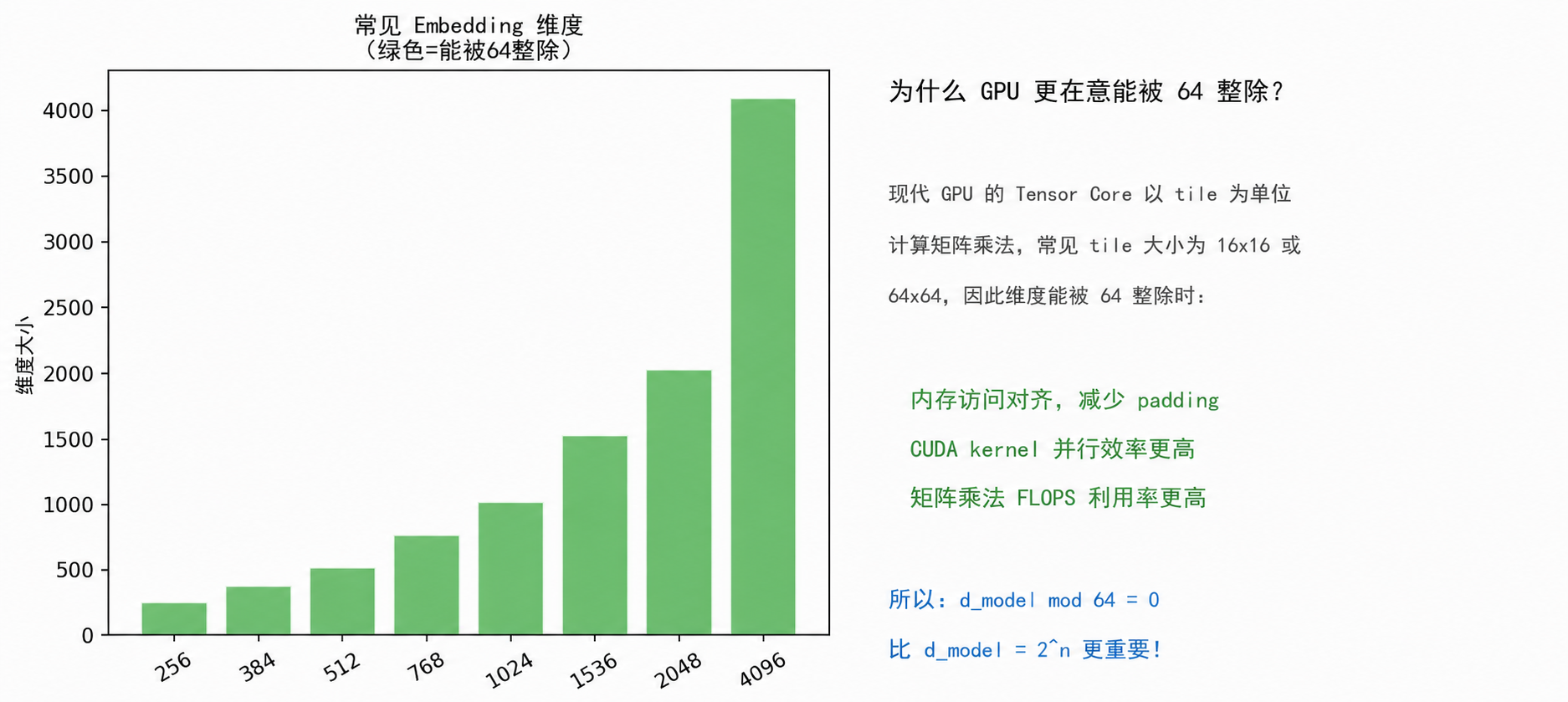
图2:现代 GPU 更在意能被 64 整除,而非 2 的次幂
深度学习中,GPU 的 Tensor Core 以 tile 为单位做矩阵乘法,常见 tile 大小为 16×16 或 64×64。因此:
d_model mod 64 = 0 比 d_model = 2^n 更重要!!!! tip "一句话总结"
768、1536、384 等维度来源于 Transformer 的注意力结构,它们满足"能被 64 整除"的 GPU 优化要求,而不是来自"2 的次幂"这个传统计算机工程原则。
顺带一提,维度越大不一定越好——训练数据质量、对比学习设计、损失函数,这些才是决定 Embedding 模型效果的关键。高维有时反而带来更多冗余和噪声。
Q2 语义空间之谜
以前 Word2Vec 好像大家通用,为什么现在每个 Embedding 模型都有自己的"空间"?它们是怎么训练的?
静态词向量 vs 上下文感知向量
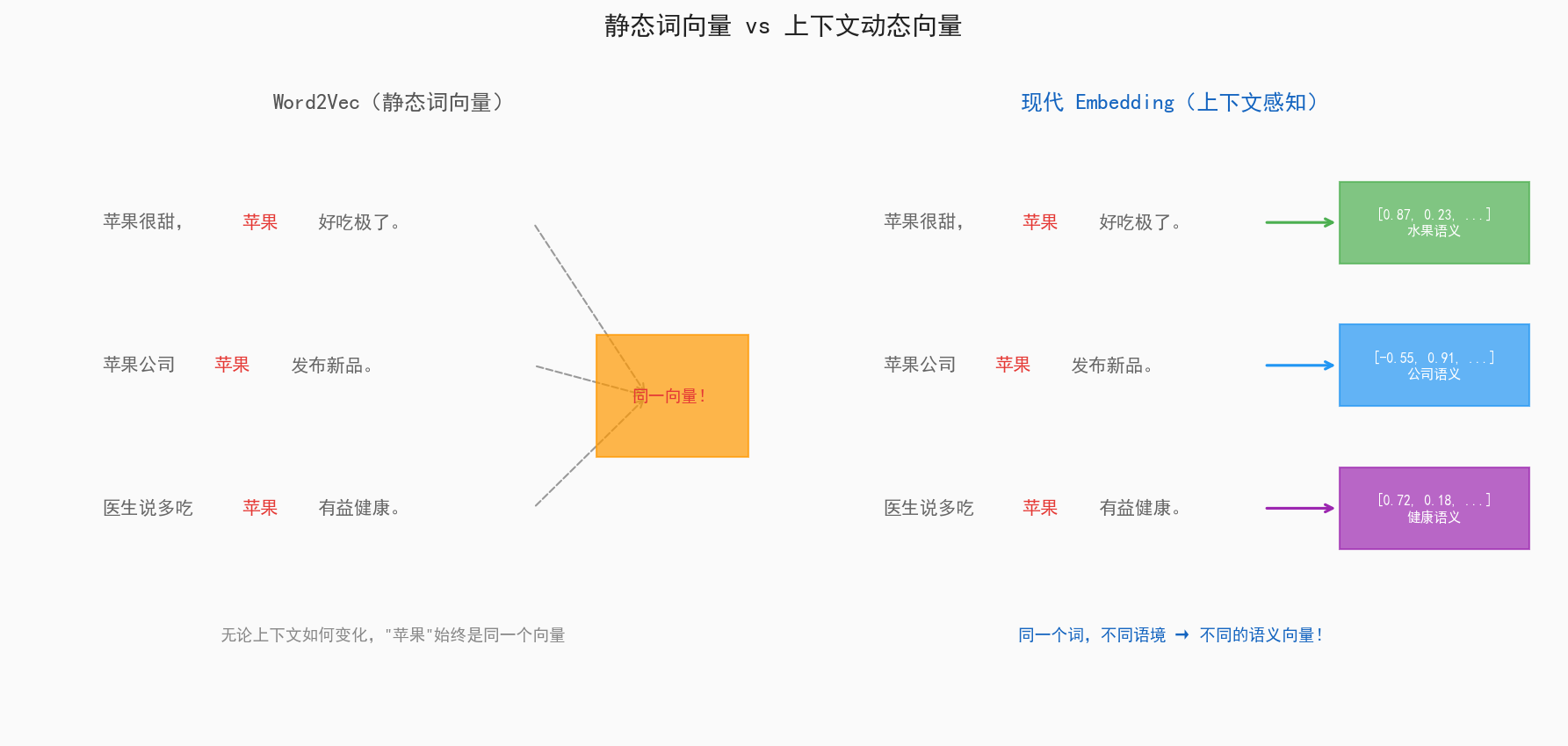
图3:静态词向量 vs 上下文感知向量*
Word2Vec 时代,"苹果"永远只有一个向量。不管是"苹果很甜"还是"苹果公司发布新品",向量完全相同。
这叫静态 Embedding(Static Embedding),代表:Word2Vec、GloVe、FastText。
大家之所以"通用",是因为词表是固定的,整个语义空间是全局共享的——像一本公开词典。
现代 Embedding 的根本变化:语义任务 × 上下文
现代 Embedding 追求的不再只是"词语编码",而是:
- 句子语义
- 文档语义
- 检索语义
- 多语言对齐
- 推理语义
……不同任务需要不同的"语义空间结构",这就是为什么模型越来越多。
语义空间是怎么训练出来的?
现代 Embedding 的核心训练方法是对比学习(Contrastive Learning):
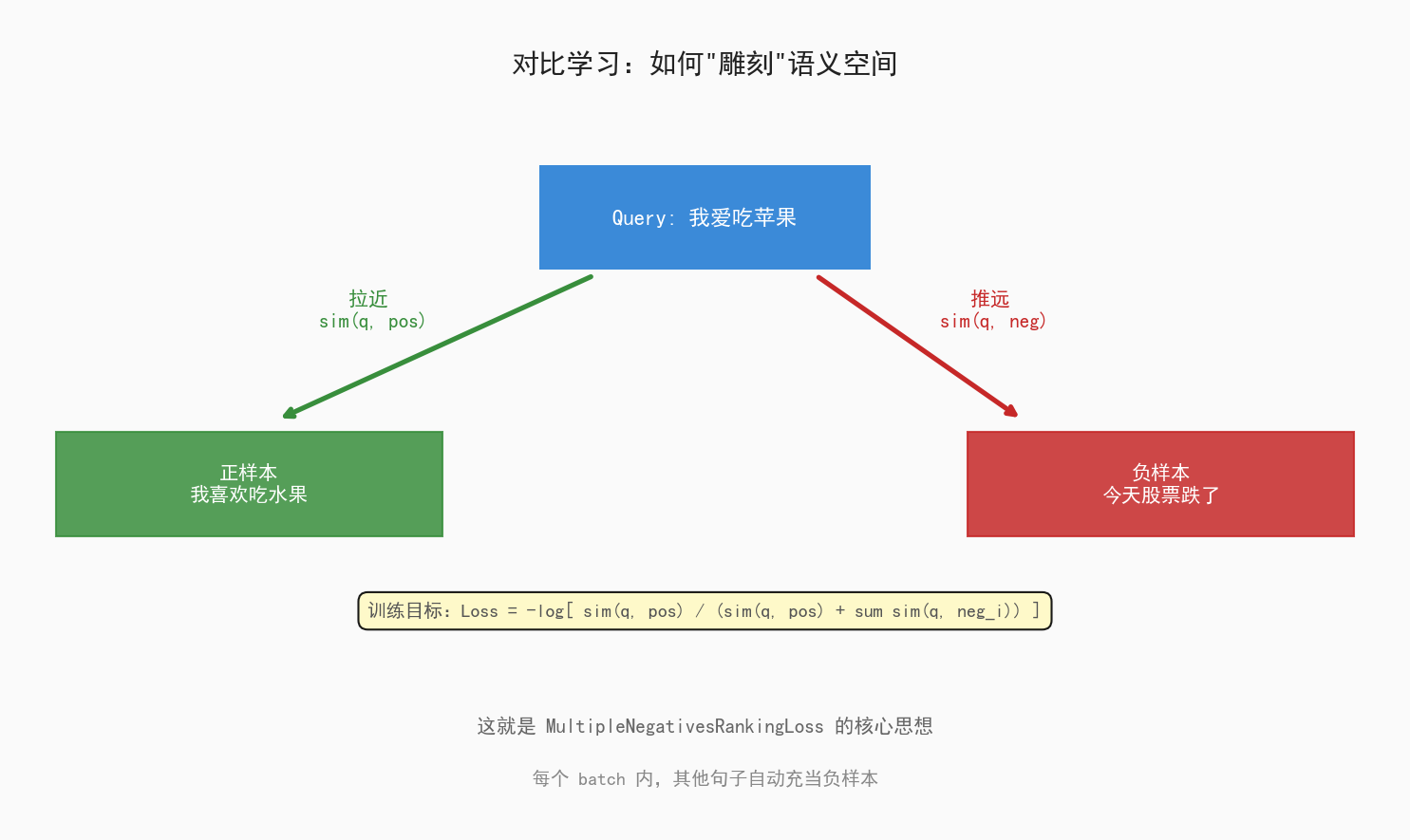
图4:对比学习的核心——拉近语义相关,推远语义无关
你可以把 Embedding 模型理解成一个"高维空间雕塑家"——它不断调整"哪些句子靠近,哪些句子远离",最终形成一个语义几何空间。
不同模型,本来就不在同一个坐标系
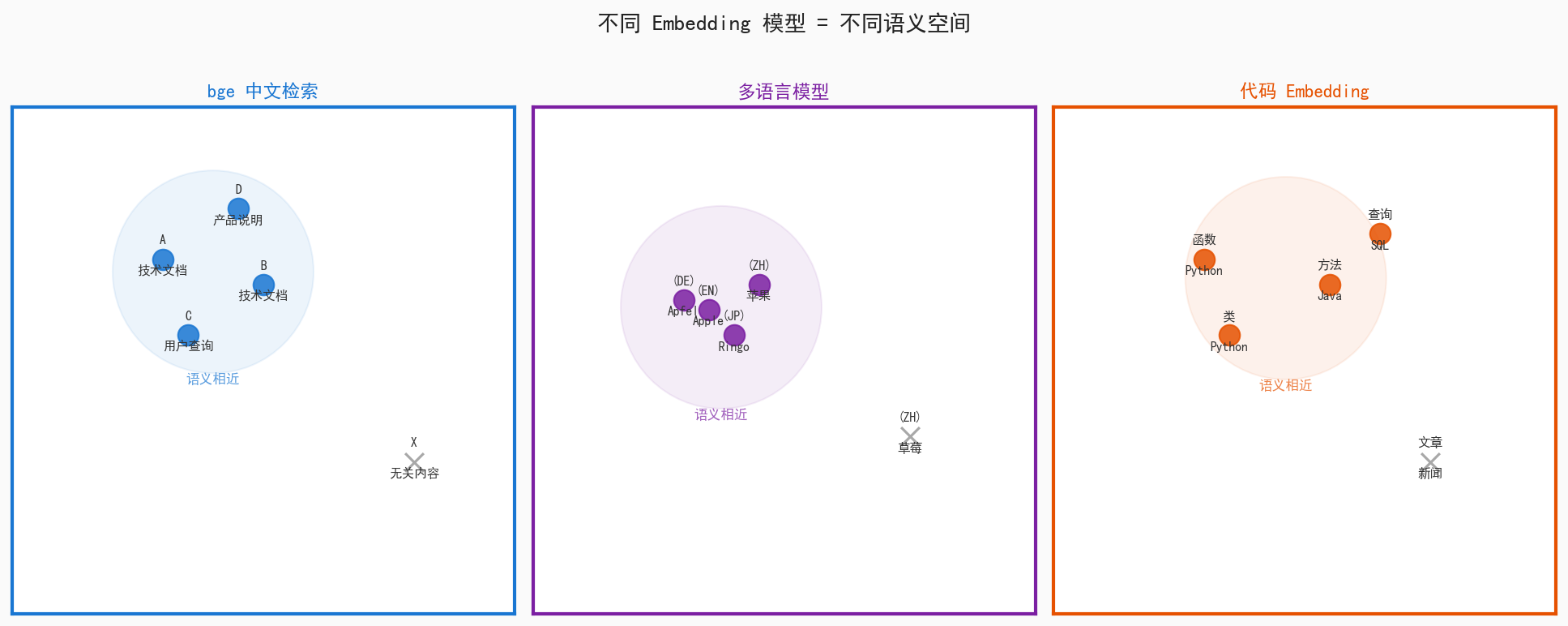
图5:三种不同的 Embedding 模型,各自形成不同的"语义聚类结构"*
模型A 里"苹果" = [1.2, 0.8],模型B 里"苹果" = [-7.3, 91.2],两个都没问题。因为真正重要的不是绝对坐标,而是相对距离关系。
这和地图投影非常像——墨卡托投影和球面投影坐标体系不同,但城市之间的相对关系仍然保留。
!!! warning "注意"
正因如此,A 模型生成的 query 和 B 模型生成的 document 通常不能混用——它们不在同一个语义空间里,混用效果会崩。
常见 Embedding 模型对比
| 模型代表 | 擅长方向 |
|---|---|
| bge 系列 | 中文检索,BGE 特有指令格式 |
| E5 系列 | 通用检索,多语言支持好 |
| jina-embedding | 长文本,支持 8K+ tokens |
| voyage-retrieval | 企业级检索,质量高 |
| code-embedding | 代码语义搜索 |
!!! tip "一句话总结"
以前 Word2Vec 是"全世界共享一本词典"。现在的 Embedding 是"每个模型都在学习自己的语义几何空间"。这些空间没有统一坐标系,不要求绝对值一致,只要求"语义距离关系"正确。
Q3 上手实践
如果要自己训练一个 Embedding 模型,应该从哪里开始?
好消息是:现在自己训练一个"小型 Embedding 模型"已经没有以前那么难了。
三条训练路线对比
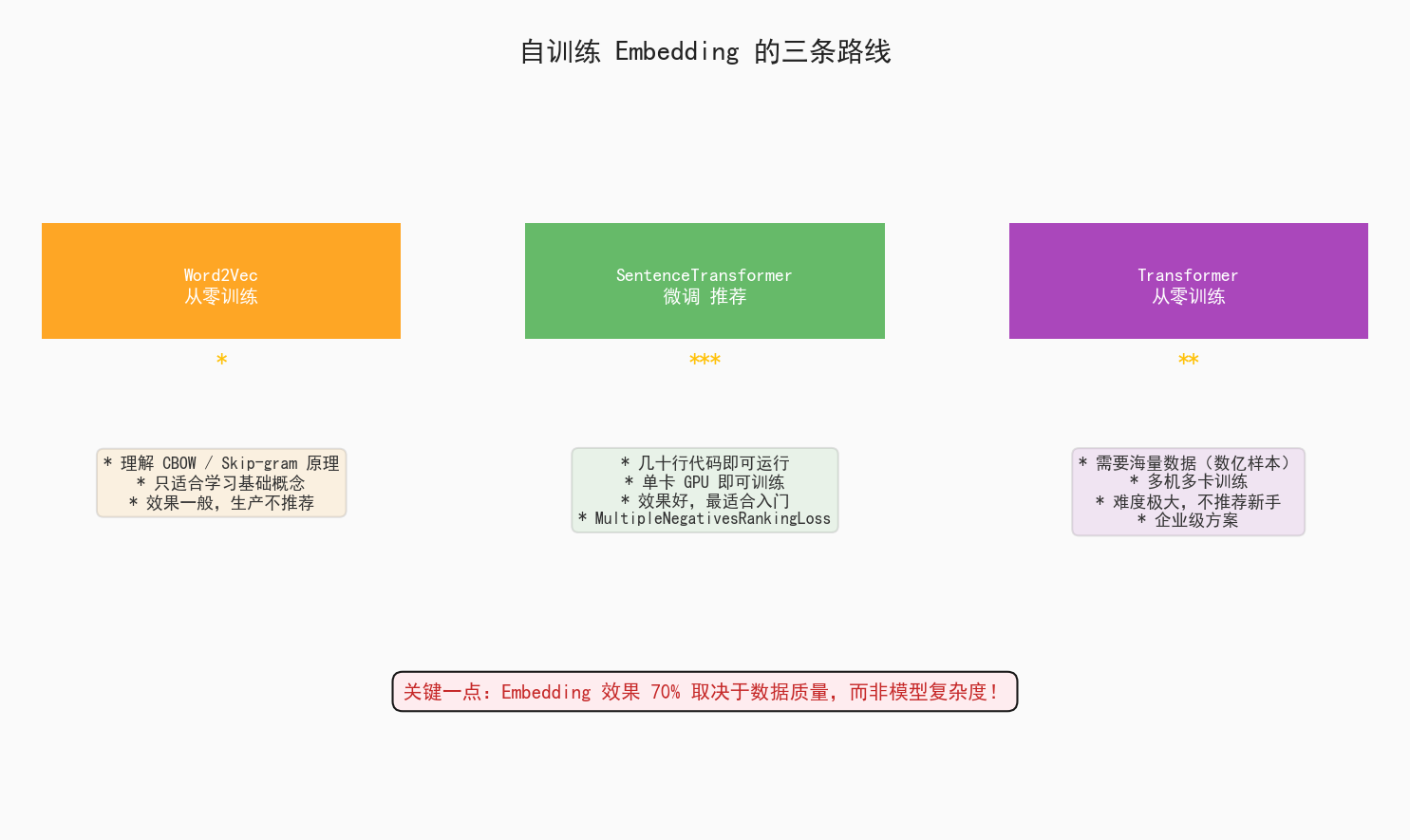
图6:三条训练路线对比,推荐新手从 SentenceTransformer 微调入门
推荐方案:SentenceTransformer 微调
训练的核心目标:学习函数 f(x) → R^d,语义相近的输入映射后向量接近;语义不同的,向量远离。
第一步:准备训练数据
Embedding 训练数据本质是"相似句子对":
| text1(锚点) | text2(正样本) |
|---|---|
| 我喜欢苹果 | 我爱吃水果 |
| 深度学习是什么 | 神经网络介绍 |
| 北京天气 | 今天北京下雨 |
第二步:运行最小可用代码
from sentence_transformers import SentenceTransformer, InputExample
from sentence_transformers.losses import MultipleNegativesRankingLoss
from torch.utils.data import DataLoader
# 1. 加载预训练中文模型
model = SentenceTransformer('BAAI/bge-small-zh')
# 2. 准备训练数据(句子对)
train_examples = [
InputExample(texts=["我喜欢苹果", "我爱吃水果"]),
InputExample(texts=["深度学习是什么", "神经网络介绍"]),
InputExample(texts=["北京天气", "今天北京下雨"]),
]
# 3. 定义数据加载器和损失函数
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=2)
train_loss = MultipleNegativesRankingLoss(model)
# 4. 开始训练
model.fit(
train_objectives=[(train_dataloader, train_loss)],
epochs=1,
warmup_steps=10
)
# 5. 保存模型
model.save("./my_embedding_model")第三步:验证效果
model = SentenceTransformer("./my_embedding_model")
emb1 = model.encode("我喜欢苹果")
emb2 = model.encode("我爱吃水果")
print(emb1.shape) # (384,)
from sklearn.metrics.pairwise import cosine_similarity
score = cosine_similarity([emb1], [emb2])
print(score) # 相近句子分数高 -> 训练成功!!! warning "关键提示"
大型 Embedding 模型(如 E5、bge-large)和小模型原理完全相同,区别只在于样本量(数亿 vs 数千)、batch size(32768 vs 16)和负样本池大小。
数据才是真正的关键
这是很多人忽视的点:
Embedding 效果上限 ≈ 70% 取决于数据质量你训练 Embedding,本质上是在训练"什么叫接近"——你在定义语义空间里的距离函数。数据决定了这个距离函数的上限。
总结
- 768/1536/384 来自 Transformer 结构:n_heads × d_head
- 每个模型语义空间不同,因为训练目标不同,空间没有统一坐标系
- 入门推荐 SentenceTransformer 微调,关键在数据质量
